最近每天打开头条,里面一半以上的内容是关于ChatGPT的, 有讲基础原理的,有视频讲如何用来写博客赚钱的,有说如何开启了AIGC时代的。朋友圈里面Monica小姐的podcast邀请各路researcher,PM和投资人讨论Large Language Model (LLM)的现状和未来。微信各种群里,朋友们晒调戏ChatGPT(比如写首诗讽刺门前只传球不射门的人)的各种截图,朋友私信问我ChatGPT能推理吗。NLP的海龟创始人预测了围绕ChatGPT国内各个大小企业的入场姿势和终局。我感受到了ChatGPT的火爆。终于,上周我妈和我们一家微信视频时以一如既往的强提醒加教导的口吻对我说“你有没有好好学习ChatGPT!?”, 那一刻,我知道ChatGPT的普及率了。
自己从读了InstructGPT的paper,从最初试用ChatGPT问C罗梅西谁更强,到现在去给娃看preschool要先问问“what are some good questions to ask when touring preschools?”,受伤了问问副韧带和半月板受伤如何恢复的更快,技术上问问 “how to let only the invited user to access the website, and also preventing them to share the invitation to others or publicly?”, coding时通过问“how to plot a barchart using a dictionary in python with x-axis using key and y-axis using values”, “set the x-labels to increment by 1”, “sort the dictionary by key before plot”帮我写代码。ChatGPT已经被我习惯性的用来解决生活和工作中的一些实际问题。
最近在思考从web1.0, web2.0到web 3.0的演化中,加之文字,图像到视频的模态变化,Stable Diffusion, ChatGPT, LLM让我们展望到互联网未来的形态可能是什么样子。
从web形态(1.0, 2.0 到 3.0)和模态或信息的丰富度(文字,图像,视频,沉浸式VR)两个维度出发生成12种组合,过去30年互联网的很多产品恰好为例子坐落在每个组合里。从中可以看出web的一些演化规律,也可以展望未来可能出现的产品形态,也可猜想Artificial General Intelligence(AGI)实现后我们的生活会变成什么样子。
| web 1.0 (read)(PGC) PC时代 | web 2.0 (read + write)(UGC) 移动互联网 | web 3.0 (read+write+execute) (AIGC) 智能助手时代 | |
| 文字 | Portal: 门户网站(新浪,网易,搜狐,雅虎,AOL)上的文章 | SNS: bbs,饭否,早期文字为主的twitter, 早期text status update为主的facebook | (Powered by ChatGPT ) 强智能+个人助手:(概括):旅行计划助手, 文章总结助手(生成): 写文章 写文案 (e.g. Jasper.AI, NotionAI) |
| 图像 | 门户网站上的图片 | (概括):看图讲故事(生成):图片生成 (e.g. Midjourney, Stable Diffusion, DALLE-E2) | |
| 视频 | 传统视频直播 | youtube(长), TikTok (短) | (概括)视频概括(生成):生成视频 (e.g. Synthesis)基于prompt engineering的创作 + 社交 |
| 沉浸式体验(VR) | 早期无社交功能的体验(过山车游戏,参观博物馆) | 用户创作的VR场景, 具有社交属性 | 更真切沉浸式多感官体验+基于prompt engineering的创作内容 + 社交分享终极形态:(元宇宙?黑镜?) |
Web1.0的结构是一对多,也就是只有平台背后的专业编辑生产内容(如门户网站),用户去consume。从用户角度讲,这一代的web只有“read”的属性(i.e.用户只能consume这些信息,不能自己发布)。早期的中国三大门户,还有美国的门户如雅虎AOL等都是Web1.0时代的代表。Web1.0时代我们在门户网站上看编辑撰写的文章,看新闻,浏览图片。体育比赛很多是文字直播或者图文直播。后来带宽提高后有了视频直播。Google Cardboard早期的体验类demo(过山车游戏,参观博物馆等)在网络结构上仍然属于Web1.0。因为内容是公司制作的,且没有社交属性。这个时代基本是PC机的时代。
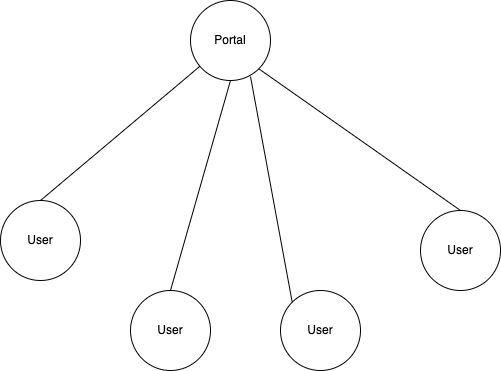
Web2.0的结构是多对多,或者点对点。以移动互联网和社交媒体(Social Network Service)的出现为代表,这里最大的不同是用户不仅consume内容,同时也是内容的创造和发布者。从用户角度讲,这一代的web增加了write的属性。大众用户可以在bbs上发帖,在校内网,facebook或微博上发状态,后来又可以分享图片,于是Instagram出现了。分享视频,于是出现了Youtube,优酷,土豆。现在到了短视频时代,出现了抖音,快手等。

Web3.0(这里的Web3.0指的是相对于Web1.0和2.0之后的semantic web或 excutable web, 而非区块链界提到的去中心化的Web3)的设想是在read和write的基础上加了一个execute(执行)。Read和write好理解,上面提过,Read就是用户可以consume内容,write的就是用户可以生产发布内容。那如何理解这个execute呢?用户如何去运行或执行web3.0呢?我们通常只说执行一个程序。这就先要说到semantic web,因为今天的互联网是基于文本和http协议的,文本的大部分语言是自然语言(除了少数的人工语言如代码,数学表达等)。这种基于http协议的很多很多文本很难在语义上关联起来让机器理解。比如网站1说”爱因斯坦创立了相对论“,网站2说”20世纪影响力第一的科学理论是相对论”,我们想知道”20世纪最有影响力的科学家是谁?“。这就需要把这两部分信息结构化,比“如爱因斯坦”是个人名,“相对论”是一个理论的名字,“20世纪”一个时间段,“影响力第一”是一个排名。自然语言和结构化过之后的自然语言的区别就如同电脑上的文件系统(filesystem)和数据库(database)的区别。今天的web相当于一个filesystem,不可执行(比如没有关联语义所以不可被查询),假设能转化成一个数据库(有schema和table之间的joining key),就可以查询了(比如:select name from scientists_theory_table where theory = (select theory_name from theory_influence_table where rank=1 and year between ‘1901’ and ‘2000’)) 。semantic web的初衷是把当今的web通过一种标准格式转化为结构化的语义网,这样机器就可以关联,而后可以查询,所有信息根据语义相关联。但是实现semantic的难度很大, 比如全网的数据量之大,和人工语言的歧义(ambiguity)等。所以,web2.0跨越到web3.0的主要障碍是机器无法理解非结构化的自然语言。
然而,ChatGPT在performance上突破一个奇点达到了初步”理解“自然语言的程度。这里的”理解“带引号是因为ChatGPT是根据统计概率填下一个词的方式来生成回答。和人类理解的方式不同。但比之前的AI的突破在于:它是大部分情况的回答让人感觉像人回答(类似通过图灵测试)的跨多任务通用模型,所以让人觉得是它理解了问题的。这样,就从另外一个方式(即用较强人工智能理解了自然语言,instead of把基于http协议的文本网络结构化为semantic web)达到了异曲同工的效果:就是可执行。上面两段我们说的read和write是从用户角度出发的,那这个execute主体是谁呢?是机器还是用户呢?我觉得应该依然是用户,是用户以ChatGPT来执行”web”。那如何理解用户以ChatGPT为工具来执行web呢?虽然ChatGPT的paper还没有公布,基于它前身的instructGPT用的pre-trained model是GPT3的,GPT3的训练数据来源于以下:CommonCrawl (410 billion tokens, 网页的数据),WebText2 (19 billion tokens), 两本书(12 billion, 55 billion tokens), 和维基百科(3 billion)。虽然这些数据只是全网数据的一个小子集,但是数据量已经很大,可预见以后随着LLM规模更大,训练的数据量也会更大。我们暂且粗略的把这样大的数据等同于web, 就相当于ChatGPT读过了web,并且理解了,那么我们用ChatGPT的时候就相当于运行ChatGPT通过web data训练出的模型来做inference,类似于把web当做一个app来执行它。这就解释了web3.0的executable的属性。再回到上段web2.0关于爱因斯坦的两个网页,因为ChatGPT的训练数据包括了这些网页,并且通过模型理解了它们之间的关联,所以就有能力回答”20世纪最有影响的科学家是谁”这样的问题。所以,从网络结构上就变成了下图这样。
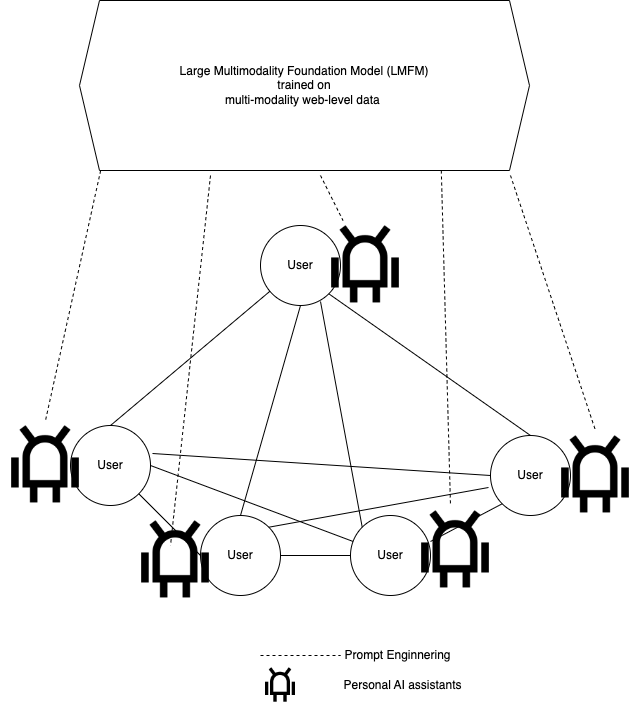
综上所述,从web2.0演化到web3.0的关键是让web变得machine-readable and – understandable,从而可以执行自动化任务。 有两种方式实现: 1)把http协议下的文本互联网转化为semantic web; 2) 通过让AI更智能来理解现在的基于http文本的web。ChatGPT是通过第二种方式实现了,而且有一个额外的benefit:生成前所未有的内容。因为第一种方式即使实现,我们也只能检索已有信息。但第二种方式,因为LLM的生成式模型的本质,可以生成新的内容(包括文本,图像,视频等),这就让web3.0定义它的executable属性基础上有了可以让机器生产内容的能力。所以内容的生产者,web1.0时代是少数门户网站的专业编辑(Professionally-generated Content (PGC)), web2.0时代是互联网用户的普罗大众(User-Generated Content (UGC)), web3.0时代是人以智能机器为工具来创造内容(AI-Generated Content), 开启了AIGC的新时代。
下一篇(如果ever写了)打算详细聊聊web3.0时代从目前的文本模态演化到最终“高逼真多感官沉浸式体验下分享通过prompt engineering创造内容的社交”这个路径(开头表格的最右边一列)中会出现什么有趣的产品。也许这个终极形态是类似《黑镜》中的那样或者元宇宙?
文: ripple 校订:energetic